
Apache Spark and Delta Lake
Guia do Engenheiro Capítulo 1


NOTA | Todo o conteúdo é embasado no meu dia a dia e na documentação da Databricks e do próprio Spark através do site e do próprio github, lembrando que o spark é open source e todo mundo tem acesso.
CAPÍTULO 1: Introdução ao Spark
Vamos explorar a arquitetura básica de um cluster, aplicação Spark e APIs, estruturas do Spark usando DataFrames e SQL.
Ao longo do caminho, vamos abordar os conceitos do Spark para que você possa começar a usar o Spark imediatamente.
Vamos começar com alguns termos e conceitos básicos, ok?!.
Arquitetura Básica do Spark

Normalmente, quando você pensa em um "computador", você pensa em uma máquina única em sua mesa em casa ou no trabalho. Essa máquina funciona perfeitamente bem para assistir filmes ou trabalhar com software.
No entanto, como muitos usuários provavelmente experimentam em algum momento, há algumas coisas que seu computador não é poderoso o suficiente para fazer. Uma área particularmente desafiadora é o processamento de dados.
Máquinas únicas não têm poder e recursos suficientes para realizar cálculos em enormes quantidades de informações (ou o usuário pode não ter tempo para esperar a conclusão do cálculo).
Um cluster, ou grupo de máquinas, combina os recursos de muitas máquinas, permitindo-nos usar todos os recursos acumulados como se fossem um só. Agora, um grupo de máquinas sozinho não é poderoso; você precisa de um framework para coordenar o trabalho entre elas. O Spark é uma ferramenta exatamente para isso, gerenciando e coordenando a execução de tarefas em dados em um cluster de computadores.
O cluster de máquinas que o Spark utilizará para executar tarefas será gerenciado por um gerenciador de cluster como o gerenciador de cluster Standalone do Spark, YARN ou Mesos.
Em seguida, submetemos Aplicação Spark a esses gerenciadores de cluster, que concederão recursos ao nosso aplicativo para que possamos concluir nosso trabalho.
Aplicação Spark
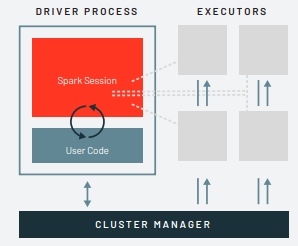
O Spark consistem em algo muito parecido de uma orquestra, o maestro é o driver e os componentes dessa orquestra são os executores.

O driver é responsável por três coisas:
1- Manter informações sobre o Spark;
2- Responder ao programa ou entrada do usuário; e analisar, distribuir e agendar o trabalho entre os executores (definidos momentaneamente). O processo driver é absolutamente essencial — é o coração do Spark
3- Manter todas as informações relevantes durante a vida útil do aplicativo.
Os executores são responsáveis por realmente executar o trabalho que o driver lhes atribui. Isso significa que cada executor é responsável por apenas duas coisas:
1- Executar o código atribuído a ele pelo driver.
2- Relatar o estado da computação, nesse executor, de volta ao nó driver.
O gerenciador de cluster controla as máquinas físicas e aloca recursos para onde é necessário.
Isso pode ser um dos vários gerenciadores de cluster principais: o gerenciador de cluster Standalone do Spark, YARN ou Mesos. Isso significa que pode haver vários Aplicativos Spark em execução em um cluster ao mesmo tempo.
Falaremos mais detalhadamente sobre os gerenciadores de cluster nos próximos capitulos. Na ilustração abaixo, vemos à esquerda nosso driver e à direita os quatro executores. Neste diagrama, removi o conceito de nós de cluster.
O usuário pode especificar quantos executores devem cair em cada nó por meio de configurações.
NOTA | O Spark, além de seu modo de cluster, também possui um modo local. O driver e os executores são simplesmente processos, o que significa que podem estar na mesma máquina ou em máquinas diferentes. No modo local, ambos são executados (como threads) em seu computador individual em vez de em um cluster. Esse artigo contempla e foi baseado no modo local.
Revisão da aplicação do Spark, os principais pontos a entender neste momento são que:
• O Spark tem algum gerenciador de cluster que mantém uma compreensão dos recursos disponíveis.
• O processo driver é responsável por executar os comandos do nosso programa driver nos executores para concluir nossa tarefa.
Enquanto nossos executores, na maioria das vezes, sempre executarão código Spark. Nosso driver pode ser "dirigido" a partir de vários idiomas diferentes por meio das
APIs de Linguagem do Spark.
Fonte:https://spark.apache.org/docs/latest/spark-connect-overview.html
As APIs de linguagem do Spark permitem que você execute código Spark em outras linguagens. Na maior parte, o Spark apresenta alguns "conceitos" centrais em cada linguagem e esses conceitos são traduzidos em código Spark que é executado no cluster de máquinas.
Se você usar as APIs Estruturadas (Veremos mais a frente nos próximos capitulos), pode esperar que todas as linguagens tenham as mesmas características de desempenho.
NOTA | Isso é um pouco mais complexo do que estamos apresentando neste ponto, mas por enquanto, é a quantidade certa de informações para novos usuários. Ao longo da jornada irei buscar meios para aprofundar nos detalhes de como isso realmente funciona.
SCALA

O Spark é principalmente escrito em Scala, tornando-o a linguagem "padrão" do Spark.
JAVA

Mesmo que o Spark seja escrito em Scala, os autores do Spark têm sido cuidadosos para garantir que você possa escrever código Spark em Java.
PYTHON

O Python suporta quase todas as construções que o Scala suporta. Este artigo incluirá exemplos de código Python sempre que incluirmos exemplos de código Scala e existir uma API em Python.
SQL

O Spark suporta o padrão ANSI SQL 2003. Isso torna fácil para analistas e não programadores aproveitarem os poderes de big data do Spark.
R
O Spark possui duas bibliotecas R comumente usadas, uma como parte do núcleo do Spark (SparkR) e outra como um pacote mantido pela comunidade R (sparklyr).
Cada API de linguagem manterá os mesmos conceitos centrais que estão descritos acima.
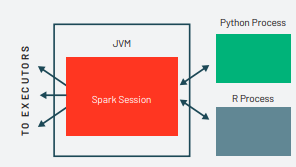
Há um SparkSession disponível para o usuário, o SparkSession será o ponto de entrada para executar o código do Spark. Ao usar o Spark a partir de um Python ou R, o usuário nunca escreve instruções JVM explícitas, mas sim escreve código Python e R que o Spark traduzirá em código que o Spark pode então executar nos executores JVM.
APIs do Spark
Embora o Spark esteja disponível em várias linguagens, o que o Spark disponibiliza nessas linguagens vale a pena mencionar. O Spark possui dois conjuntos fundamentais de APIs: as APIs de "Unstructured" de baixo nível e as APIs Estruturadas de nível mais alto. Abordarei ao longo da jornada mais detalhes sobre, mas este capítulo introdutório se concentrará principalmente nas APIs de nível mais alto.
Iniciando o Spark
Até agora, cobrimos os conceitos básicos de Aplicativos Spark. Isso tudo foi conceitual. Quando realmente começamos a escrever nosso Aplicativo Spark, vamos precisar de uma maneira de enviar comandos do usuário e dados para o Aplicativo Spark. Fazemos isso com um SparkSession.
SparkSession
Como discutido no início, controlamos nosso Aplicativo Spark por meio de um processo driver. Este processo driver se manifesta para o usuário como um objeto chamado SparkSession.
A instância SparkSession é a maneira como o Spark executa manipulações definidas pelo usuário em todo o cluster. Existe uma correspondência um para um entre um SparkSession e um Aplicativo Spark.
Em Scala e Python, a variável está disponível como spark quando você inicia o console. Vamos dar uma olhada no SparkSession em Scala e/ou Python.
Em Scala, você deve ver algo como:
// Importando a classe SparkSession
import org.apache.spark.sql.SparkSession
// Criando a SparkSession
val spark = SparkSession.builder
.appName("Exemplo")
.getOrCreate()
// Mostrando o resultado
println(spark)
Resultado:
org.apache.spark.sql.SparkSession@2s4d5a7a1
Em Python, você verá algo como:
# Importando a classe SparkSession
from pyspark.sql import SparkSession
# Criando a SparkSession
spark = SparkSession.builder \
.appName("Exemplo") \
.getOrCreate()
# Mostrando o resultado
print(spark)
resultado:
<pyspark.sql.session.SparkSession object at 0x7efda4c1ccd0>
Agora vamos realizar a tarefa simples de criar uma série de números.
Esta série de números é como uma coluna nomeada em uma planilha.
%scala
val myRange = spark.range(1000).toDF(“number”)
%python
myRange = spark.range(1000).toDF(“number”)
Você acabou de executar seu primeiro código Spark! Criamos um DataFrame com uma coluna contendo 1000 linhas com valores de 0 a 999. Esta série de números representa uma coleção distribuída. Quando executado em um cluster, cada parte desta série de números existe em um executor diferente. Este é um DataFrame do Spark.
DataFrames
Um DataFrame é a API Estruturada mais comum e simplesmente representa uma tabela de dados com linhas e colunas.
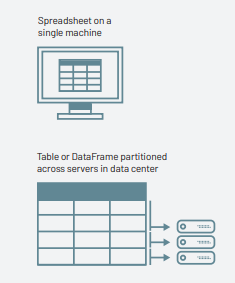
A lista de colunas e os tipos nessas colunas formam o esquema. Uma analogia simples seria uma planilha com colunas nomeadas. A diferença fundamental é que, enquanto uma planilha fica em um único computador em um local específico, um DataFrame do Spark pode abranger milhares de computadores.
A razão para colocar os dados em mais de um computador deve ser intuitiva: ou os dados são muito grandes para caber em um único computador, ou simplesmente levaria muito tempo para realizar esse cálculo em um único computador.
O conceito de DataFrame não é exclusivo do Spark. R e Python ambos têm conceitos semelhantes. No entanto, os DataFrames em Python/R (com algumas exceções) existem em um único computador em vez de vários computadores.
Isso limita o que você pode fazer com um DataFrame específico em Python e R aos recursos que existem naquele computador específico. No entanto, como o Spark tem interfaces de linguagem para Python e R, é muito fácil converter DataFrames do Pandas (Python) em DataFrames do Spark e DataFrames do R em DataFrames do Spark (em R).
Exemplo, conversão de dataframe pandas para spark
DE:
import pandas as pd
Para:
import pyspark.pandas as ps
NOTA | O Spark possui várias abstrações principais: Conjuntos de Dados, DataFrames, Tabelas SQL e Conjuntos de Dados Distribuídos Resilientes (RDDs). Essas abstrações representam todas coleções distribuídas de dados, no entanto, elas têm interfaces diferentes para trabalhar com esses dados. As mais fáceis e eficientes são os DataFrames, que estão disponíveis em todas as linguagens. Mais a frente cobriremos mais itens dessa nossa jornada, espero que tenham gostado.
Partições
Para permitir que cada executor execute o trabalho em paralelo, o Spark divide os dados em pedaços chamados partições. Uma partição é uma coleção de linhas que está em uma máquina física em nosso cluster.
As partições de um DataFrame representam como os dados estão distribuídos fisicamente em seu cluster de máquinas durante a execução. Se você tiver uma partição, o Spark terá apenas um paralelismo de um, mesmo que você tenha milhares de executores. Se você tiver muitas partições, mas apenas um executor, o Spark ainda terá um paralelismo de um, porque há apenas um recurso de computação.
Uma coisa importante a se notar é que, com DataFrames, não manipulamos (na maioria das vezes) as partições manualmente (individualmente). Simplesmente especificamos transformações de alto nível dos dados nas partições físicas e o Spark determina como esse trabalho será executado no cluster. APIs de nível inferior existem (via a interface Resilient Distributed Datasets) e irei trazer um exemplo ao longo da jornada.
Transformações
No Spark, as estruturas de dados principais são imutáveis, o que significa que não podem ser alteradas depois de criadas. Isso pode parecer um conceito estranho no início, se você não pode mudá-lo, como você deve usá-lo?
Para "alterar" um DataFrame, você terá que instruir o Spark sobre como gostaria de modificar o DataFrame que você tem para o que deseja. Essas instruções são chamadas de transformações. Vamos realizar uma transformação simples para encontrar todos os números pares em nosso DataFrame atual.
%scala
val dividePor2 = myRange.where("number % 2 = 0")
%python
dividePor2 = myRange.where("number % 2 = 0")
Você perceberá que esses comandos não retornam nenhuma saída, isso porque só especificamos uma transformação abstrata e o Spark não agirá nas transformações até que chamemos uma ação, discutida em breve.
As transformações são o cerne de como você expressará sua lógica de negócios usando o Spark. Existem dois tipos de transformações, aquelas que especificam dependências estreitas e aquelas que especificam dependências amplas.
Transformações consistindo em dependências estreitas (vamos chamá-las de transformações estreitas) são aquelas em que cada partição de entrada contribuirá para apenas uma partição de saída. No trecho de código anterior, nossa instrução where especifica uma dependência estreita, onde apenas uma partição contribui para no máximo uma partição de saída.
Uma transformação do tipo dependência ampla (ou transformação ampla) terá partições de entrada contribuindo para muitas partições de saída. Você frequentemente ouvirá isso ser chamado de shuffle, onde o Spark trocará partições em todo o cluster.
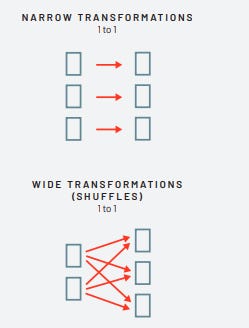
Com transformações estreitas, o Spark realizará automaticamente uma operação chamada de encadeamento em dependências estreitas, o que significa que, se especificarmos múltiplos filtros em DataFrames, todos serão realizados na memória.
O mesmo não pode ser dito para shuffles. Quando realizamos um shuffle, o Spark gravará os resultados no disco. Você verá muitas discussões sobre a otimização de shuffle na web porque é um tópico importante, mas por enquanto tudo é o que você precisa entender.
Agora vemos como as transformações são simplesmente maneiras de especificar diferentes séries de manipulação de dados. Isso nos leva a um tópico chamado avaliação preguiçosa.
Avaliação Preguiçosa or Lazy Evaluation
A avaliação preguiçosa significa que o Spark esperará até o último momento para executar o grafo de instruções de computação.
No Spark, em vez de modificar os dados imediatamente quando expressamos alguma operação, construímos um plano de transformações que gostaríamos de aplicar aos nossos dados de origem.
O Spark, ao esperar até o último minuto para executar o código, compilará este plano a partir de suas transformações brutas do DataFrame para um plano físico eficiente que será executado o mais eficientemente possível em todo o cluster.
Isso fornece benefícios imensos ao usuário final porque o Spark pode otimizar todo o fluxo de dados de ponta a ponta.
Um exemplo disso é algo chamado "empurrar de predicado" em DataFrames. Se construirmos um grande trabalho do Spark, mas especificarmos um filtro no final que só requer que recuperemos uma linha de nossos dados de origem, a maneira mais eficiente de executar isso é acessar o único registro que precisamos. O Spark realmente otimizará isso para nós, empurrando automaticamente o filtro.
Ações
As transformações nos permitem construir nosso plano de transformação lógica. Para acionar a computação, executamos uma ação. Uma ação instrui o Spark a calcular um resultado a partir de uma série de transformações. A ação mais simples é o count, que nos dá o número total de registros no DataFrame.
%Scala
dividePor2 .count()
Agora vemos um resultado! Existem 500 números divisíveis por dois de 0 a 999 (grande surpresa!). Agora, count não é a única ação. Existem três tipos de ações:
1 - Ações para visualizar dados no console;
2 - Ações para coletar dados em objetos nativos na linguagem respectiva;
3 - Ações para escrever em fontes de dados de saída.
Ao especificarmos nossa ação, iniciamos um trabalho do Spark que executa nossa transformação de filtro (uma transformação estreita), depois uma agregação (uma transformação ampla) que realiza as contagens em uma base de partição por partição, depois um collect que traz nosso resultado para um objeto nativo na linguagem respectiva.
Para o artigo não ficar muito grande, vou me despedindo por aqui, espero que tenham gostado e, no próximo fds ou meio de semana, eu estarei complementando mais a nossa jornada.
Não deixem de dar aquela contribuição, ajuda a me manter motivado em trazer conteúdo para a comunidade.
Abraços e até a próxima.