
Apache Spark and Delta Lake Capítulo 2 Spark 3.5.1 - Web UI
Guia do Engenheiro Capítulo 2: Spark 3.5.1 - Web UI


NOTA | Todo o conteúdo é embasado no meu dia a dia e na documentação da Databricks e do próprio Spark através do site e do próprio github, lembrando que o spark é open source e todo mundo tem acesso.
CAPÍTULO 2: Spark 3.5.1 - Web UI
O Apache Spark fornece um conjunto de interfaces de utilizador da Web (UIs) que pode utilizar para monitorizar o estado e o consumo de recursos do seu cluster Spark.
Iremos falar sobre:
Jobs Tab e Jobs detail
Stages Tab e Stage detail
Storage Tab
Environment Tab
Executors Tab
SQL Tab e SQL metrics
Structured Streaming Tab
Streaming (DStreams) Tab
JDBC/ODBC Server Tab
Jobs Tab
A guia trabalho exibe uma página de resumo de todos os trabalhos no aplicativo Spark e uma página de detalhes para cada trabalho. A página de resumo mostra informações de alto nível, como o estado, a duração e o progresso de todos os trabalhos e a linha de tempo geral do evento. Ao clicar em um trabalho na página de resumo, você verá a página de detalhes desse trabalho. A página de detalhes mostra ainda a linha do tempo do evento, a visualização do DAG e todos os estágios do trabalho.
As informações exibidas nesta secção são:
Usuário: usuário atual do Spark (Current Spark user)
Tempo total de atividade: Tempo desde que o aplicativo Spark foi iniciado (Time since Spark application started)
Modo de agendamento: See job scheduling
Número de tarefas por estado: Active, Completed, Failed
Linha cronológica de eventos: Apresenta, por ordem cronológica, os eventos relacionados com os executores (adicionados, removidos) “(added, removed)” e os trabalhos.

Detalhes dos trabalhos agrupados por estado: Apresenta informações pormenorizadas sobre os trabalhos, incluindo a ID do trabalho, a descrição (com uma ligação à página detalhada do trabalho), a hora de envio, a duração, o resumo das fases e a barra de progresso das tarefas



Se clicar num trabalho específico, pode ver as informações pormenorizadas sobre esse trabalho.
Jobs Detail
Esta página apresenta os detalhes de uma tarefa específica identificada pelo seu ID de tarefa.
Estado do trabalho: (em execução, bem-sucedido, falhado) = (running, succeeded, failed)
Número de fases por estado (ativo, pendente, concluído, ignorado, falhado) = (active, pending, completed, skipped, failed)
Consulta SQL associada: Ligação ao separador sql para esta tarefa
Linha do tempo do evento: Apresenta, por ordem cronológica, os eventos relacionados com os executores (adicionados, removidos) e as fases da tarefa.

Visualização do DAG: Representação visual do gráfico acíclico dirigido deste trabalho, onde os vértices representam os RDDs ou DataFrames e as arestas representam uma operação a ser aplicada no RDD.
Um exemplo de visualização de DAG para sc.parallelize(1 to 100).toDF.count()

Lista de fases (agrupadas por estado ativo, pendente, concluído, ignorado e falhado)
ID da etapa
Descrição da fase
Carimbo de data/hora de envio
Duração da etapa
Barra de progresso das tarefas
Entrada: Bytes lidos do armazenamento nesta fase
Saída: Bytes escritos no armazenamento nesta fase
Leitura da baralhação: Total de bytes de baralhamento e registos lidos, inclui tanto os dados lidos localmente como os dados lidos de executores remotos
Escrita aleatória: Bytes e registos escritos no disco para serem lidos por um shuffle numa fase futura
Stages Tab
A guia estágio exibe uma página de resumo que mostra o estado atual de todos os estágios de todos os trabalhos no app Spark.
No início da página está o resumo com a contagem de todos os estágios por status (ativo, pendente, concluído, ignorado e com falha)

No modo de programação, existe uma tabela que apresenta as propriedades dos pools.

Em seguida, são apresentados os detalhes das etapas por estado (ativa, pendente, concluída, ignorada, falhada). Nas fases ativas, é possível encerrar a fase com o link kill. Apenas nas fases falhadas é apresentado o motivo da falha. É possível aceder aos detalhes da tarefa clicando na descrição.

Stage detail
A página de detalhes da etapa começa com informações como o tempo total de todas as tarefas, resumo do nível de localidade, tamanho da leitura aleatória / registos e IDs de tarefas associadas (Locality level summary, Shuffle Read Size / Records and Associated Job IDs.)

Existe também uma representação visual do gráfico acíclico dirigido (DAG) desta fase, em que os vértices representam os RDDs ou DataFrames e as arestas representam uma operação a aplicar. Os nos são agrupados por âmbito da operação na visualização do DAG e rotulados com o nome do âmbito da operação (BatchScan, WholeStageCodegen, Exchange, etc.). Notavelmente, as operações Whole Stage Code Generation também são anotadas com o ID de geração de código. Para os estágios pertencentes ao Spark DataFrame ou à execução de SQL, isso permite fazer referência cruzada dos detalhes da execução do estágio com os detalhes relevantes na página da guia SQL da Web-UI, onde os gráficos do plano SQL e os planos de execução são relatados.

As métricas resumidas de todas as tarefas são representadas numa tabela e numa linha de tempo.
Duration of tasks.
GC time é o tempo total de recolha de lixo da JVM..
Result serialization time é o tempo gasto a serializar o resultado da tarefa num executor antes de o enviar de volta para o controlador.
Getting result time é o tempo que o condutor gasta a ir buscar os resultados das tarefas aos trabalhadores.
Scheduler delay é o tempo que a tarefa espera para ser agendada para execução.
Peak execution memory é a memória máxima utilizada pelas estruturas de dados internas criadas durante as baralhamentos, agregações e junções.
Shuffle Read Size / Records é o Total de bytes de baralhamento lidos, inclui tanto os dados lidos localmente como os dados lidos a partir de executores remotos.
Shuffle Read Fetch Wait Time é o tempo que as tarefas passaram bloqueadas à espera que os dados da baralhação fossem lidos de máquinas remotas.
Shuffle Remote Reads é o total de bytes de baralhamento lidos pelos executores remotos.
Shuffle Write Time é o tempo que as tarefas gastam a escrever dados aleatórios.
Shuffle spill (memory) é o tamanho da forma desserializada dos dados baralhados na memória.
Shuffle spill (disk) é o tamanho da forma serializada dos dados no disco.

As métricas agregadas por executor mostram as mesmas informações agregadas por executor.

Os acumuladores são um tipo de variáveis partilhadas. Fornecem uma variável mutável que pode ser atualizada em uma variedade de transformações. É possível criar acumuladores com e sem nome, mas apenas os acumuladores com nome são apresentados.

Os detalhes das tarefas incluem basicamente as mesmas informações que na secção de resumo, mas detalhadas por tarefa. Inclui também ligações para rever os registos e o número de tentativa da tarefa, se está falhar por qualquer motivo. Se existirem acumuladores nomeados, aqui é possível ver o valor do acumulador no final de cada tarefa.

Storage Tab
O separador Armazenamento apresenta os RDDs e DataFrames persistentes, se existirem, na aplicação. A página de resumo mostra os níveis de armazenamento, os tamanhos e as partições de todos os RDDs, e a página de detalhes mostra os tamanhos e a utilização de executores para todas as partições num RDD ou DataFrame.
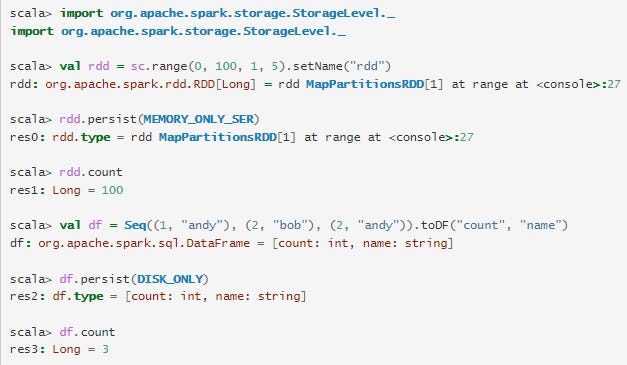

Depois de executar o exemplo acima, podemos encontrar dois RDDs listados no separador Armazenamento. São fornecidas informações básicas como nível de armazenamento, número de partições e sobrecarga de memória. Note que os RDDs ou DataFrames recentemente persistidos não são mostrados no separador antes de serem materializados. Para monitorizar um RDD ou DataFrame específico, certifique-se de que foi accionada uma operação de ação.

Pode clicar no nome do RDD "rdd" para obter os detalhes da persistência de dados, como a distribuição de dados no cluster.
Environment Tab
O separador Ambiente apresenta os valores para as diferentes variáveis de ambiente e configuração, incluindo JVM, Spark e propriedades do sistema.

Esta página de ambiente tem cinco partes. É um local útil para verificar se as suas propriedades foram definidas corretamente. A primeira parte, "Informações de tempo de execução", contém simplesmente as propriedades de tempo de execução, como versões de Java e Scala. A segunda parte, "Propriedades do Spark", lista as propriedades do aplicativo, como "spark.app.name" e "spark.driver.memory".

Clicar no link 'Propriedades do Hadoop' exibe as propriedades relativas ao Hadoop e ao YARN. Observe que propriedades como ‘spark.hadoop.*’ não são mostrados nesta parte, mas em 'Propriedades do Spark'.

'Propriedades do sistema' mostra mais detalhes sobre a JVM.

A última parte 'Classpath Entries' lista as classes carregadas de diferentes fontes, o que é muito útil para resolver conflitos de classes.
Executors Tab
O separador Executores apresenta informações resumidas sobre os executores que foram criados para a aplicação, incluindo a utilização da memória e do disco e informações sobre tarefas e baralhamento. A coluna Memória de armazenamento mostra a quantidade de memória usada e reservada para armazenar dados em cache.

O separador Executores fornece não só informações sobre os recursos (quantidade de memória, disco e núcleos utilizados por cada executor), mas também informações sobre o desempenho (tempo de GC e informações de baralhamento).

Clicar na ligação "stderr" do executor 0 mostra o registo de erros padrão detalhado na sua consola.

Clicar no link 'Thread Dump' do executor 0 exibe o thread dump da JVM no executor 0, o que é bastante útil para análise de desempenho.
SQL Tab
Se a aplicação executar consultas Spark SQL, o separador SQL apresenta informações, como a duração, os trabalhos e os planos físicos e lógicos das consultas. Aqui incluímos um exemplo básico para ilustrar este separador:
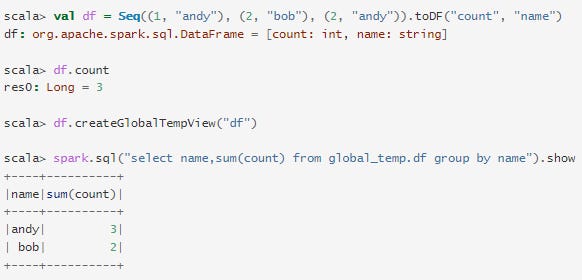

Agora, os três operadores de dataframe/SQL acima são mostrados na lista. Se clicarmos na ligação "mostrar na <console>: 24" da última consulta, veremos o DAG e os detalhes da execução da consulta.

A página de detalhes da consulta apresenta informações sobre o tempo de execução da consulta, a sua duração, a lista de trabalhos associados e o DAG de execução da consulta. O primeiro bloco 'WholeStageCodegen (1)' compila vários operadores ('LocalTableScan' e 'HashAggregate') numa única função Java para melhorar o desempenho, e métricas como o número de linhas e o tamanho do derrame são listadas no bloco. A anotação "(1)" no nome do bloco é a identificação da geração do código. O segundo bloco, "Exchange", mostra as métricas da troca de shuffle, incluindo o número de registos shuffle escritos, o tamanho total dos dados, etc.

Clicar no link 'Detalhes' na parte inferior exibe os planos lógicos e o plano físico, que ilustram como o Spark analisa, otimiza e executa a consulta. As etapas do plano físico sujeitas à otimização de geração de código em todo o estágio são prefixadas por uma estrela seguida pelo ID de geração de código, por exemplo: '*(1) LocalTableScan'
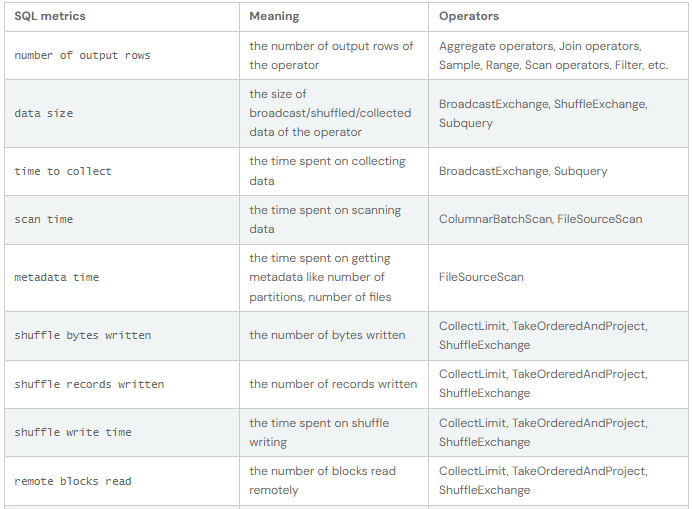
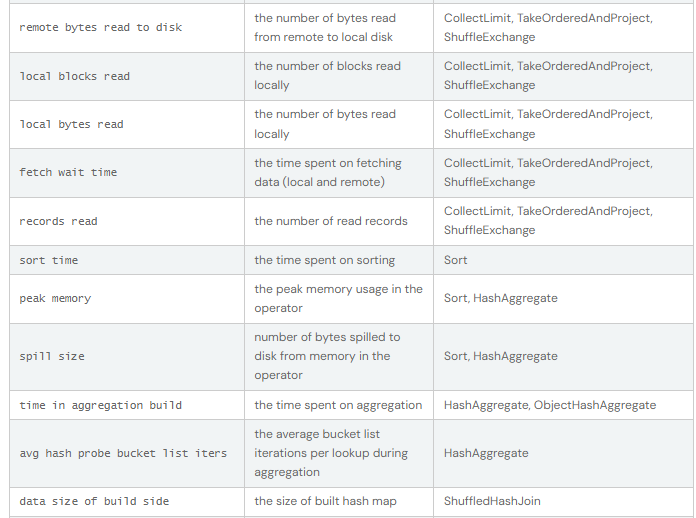
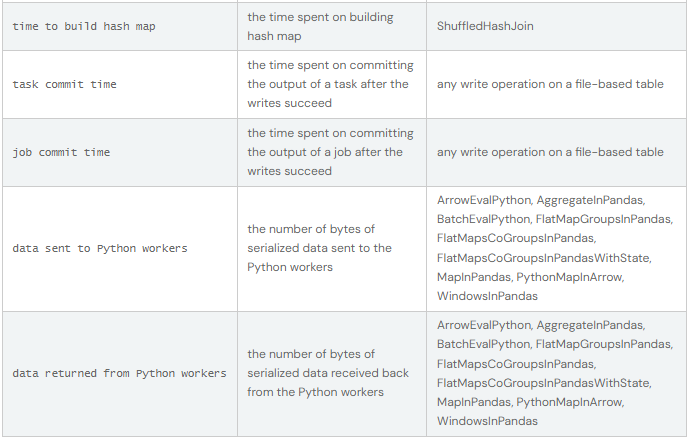
SQL metrics
As métricas dos operadores SQL são apresentadas no bloco de operadores físicos. As métricas SQL podem ser úteis quando se pretende aprofundar os pormenores de execução de cada operador. Por exemplo, "number of output rows" (número de linhas de saída) pode responder a quantas linhas são emitidas depois de um operador Filter (filtro), "shuffle bytes written total" (total de bytes escritos aleatoriamente) num operador Exchange mostra o número de bytes escritos por um shuffle.
Aqui está a lista de métricas SQL:
Structured Streaming Tab
Ao executar tarefas de Fluxo estruturado no modo de micro-lote, um separador Fluxo estruturado estará disponível na IU da Web. A página de resumo apresenta algumas estatísticas breves para consultas em execução e concluídas. Além disso, pode verificar a última exceção de uma consulta falhada. Para obter estatísticas detalhadas, clique numa "id de execução" nas tabelas.

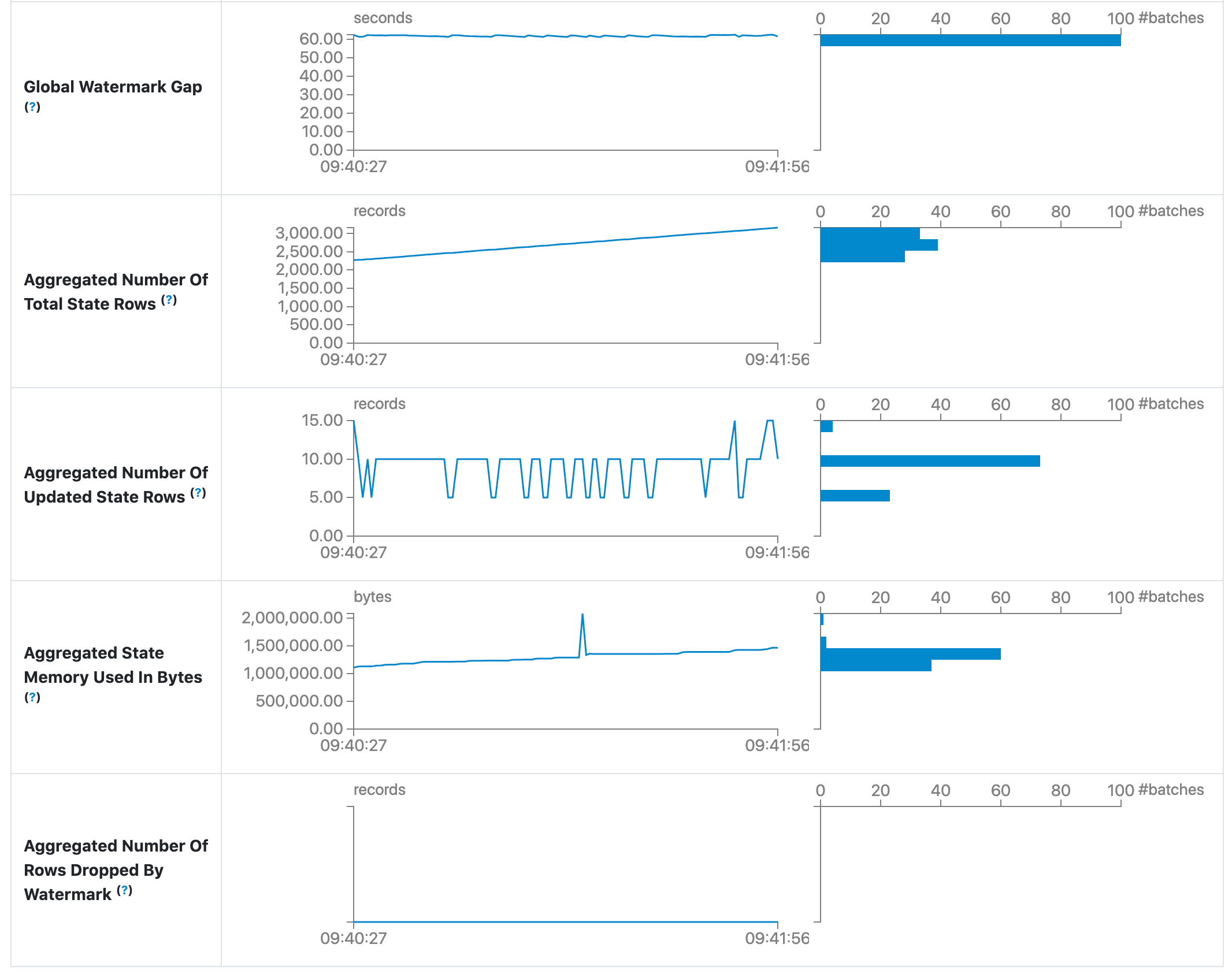
Input Rate. Taxa agregada (em todas as fontes) de chegada de dados.
Process Rate. Taxa agregada (em todas as fontes) a que o Spark está a processar os dados.
Input Rows. Número agregado (em todas as fontes) de registos processados num acionador.
Batch Duration. Duração do processo de cada lote.
Operation Duration. Quantidade de tempo necessária para executar várias operações em milissegundos. As operações monitorizadas são listadas da seguinte forma.
addBatch: Tempo necessário para ler os dados de entrada do micro-lote a partir das fontes, processá-los e escrever a saída do lote no coletor. Isso deve tomar a maior parte do tempo do micro-lote.
getBatch: Tempo gasto para preparar a consulta lógica para ler a entrada do micro-lote atual a partir das fontes.
latestOffset & getOffset: Tempo gasto para consultar o deslocamento máximo disponível para esta fonte.
queryPlanning: Tempo necessário para gerar o plano de execução.
walCommit: Tempo necessário para escrever os offsets no registo de metadados.
Global Watermark Gap. Intervalo entre o carimbo de data/hora do lote e a marca d'água global do lote.
Aggregated Number Of Total State Rows. Número agregado do total de linhas de estado.
Aggregated Number Of Updated State Rows. Número agregado de linhas de estado atualizadas.
Aggregated State Memory Used In Bytes. Memória de estado agregada usada em bytes.
Aggregated Number Of State Rows Dropped By Watermark. Número agregado de linhas de estado descartadas por marca d'água.
Sendo uma versão de lançamento antecipado, a página de estatísticas ainda está a ser desenvolvida e será melhorada em versões futuras.
Streaming (DStreams) Tab
A IU da Web inclui um separador Streaming se a aplicação utilizar o Spark Streaming com a API DStream. Este separador apresenta o atraso de agendamento e o tempo de processamento para cada micro-lote no fluxo de dados, o que pode ser útil para a resolução de problemas da aplicação de fluxo contínuo.
JDBC/ODBC Server Tab
Podemos ver este separador quando o Spark está a ser executado como um motor SQL distribuído. Ela mostra informações sobre sessões e operações SQL enviadas.
A primeira seção da página exibe informações gerais sobre o servidor JDBC/ODBC: hora de início e tempo de atividade.

A segunda secção contém informações sobre as sessões activas e terminadas.
User and IP of the connection. (Utilizador e IP da ligação.)
Session id link to access to session info. (Ligação de identificação da sessão para aceder às informações da sessão.)
Start time, finish time and duration of the session. (Hora de início, hora de fim e duração da sessão.)
Total execute is the number of operations submitted in this session. (O total de execuções é o número de operações submetidas nesta sessão.)


A terceira secção contém as estatísticas SQL das operações apresentadas.
User that submit the operation. (Utilizador que submete a operação.)
Job id link to jobs tab. (ID da tarefa, ligação ao separador das tarefas.)
Group id of the query that group all jobs together. An application can cancel all running jobs using this group id. (ID do grupo da consulta que agrupa todos os trabalhos. Uma aplicação pode cancelar todos os trabalhos em curso utilizando este identificador de grupo.)
Start time of the operation. (Hora de início da operação.)
Finish time of the execution, before fetching the results. (Hora de conclusão da execução, antes de obter os resultados.)
Close time of the operation after fetching the results.(Hora de fechamento da operação após a obtenção dos resultados.)
Execution time is the difference between finish time and start time. (O tempo de execução é a diferença entre a hora de fim e a hora de início.)
Duration time is the difference between close time and start time.(O tempo de duração é a diferença entre a hora de fecho e a hora de início.)
Statement is the operation being executed. (Declaração é a operação que está a ser executada.)
State of the process.
Started, first state, when the process begins.
Compiled, execution plan generated.
Failed, final state when the execution failed or finished with error.
Canceled, final state when the execution is canceled.
Finished processing and waiting to fetch results.
Closed, final state when client closed the statement.
Detail of the execution plan with parsed logical plan, analyzed logical plan, optimized logical plan and physical plan or errors in the SQL statement. (Detalhe do plano de execução com plano lógico analisado, plano lógico analisado, plano lógico optimizado e plano físico ou erros na instrução SQL.)

Não deixem de dar aquela contribuição, ajuda a me manter motivado em trazer conteúdo para a comunidade.
Abraços e até a próxima.