
Descomplicando a Replicação de Dados em Tempo Real!
Replicação de Dados em Near Real-Time: Desafios e Soluções


Olá, me chamo Wellikiandre Martins, me siga no linkedin e no instagram, caso queira evoluir comigo e/ou entrar na comunidade acesse https:\\datacement.com.br
Contexto
Em muitos cenários, a necessidade de replicar dados em near real-time para que possam ser utilizados pelos stakeholders é crucial. Existem várias técnicas para realizar essa replicação, mas uma das mais fascinantes é a utilização de um serviço com Kafka. Kafka oferece uma solução robusta para streaming de dados, permitindo que os times de engenharia consumam dados quase instantaneamente. No entanto, nem todas as empresas têm uma equipe de desenvolvimento capacitada para implementar e manter um serviço Kafka, o que limita seu uso em muitos ambientes corporativos.
Existem outras abordagens para replicação de dados, como fazer requisições diretamente nos sistemas OLTP (Online Transaction Processing) a nível de tabela ou através de consultas incrementais. Nesse método, coletamos pequenos lotes de dados (batch) com um controle baseado no último ID lido, data de atualização ou inserção, ou em um campo de lastupdate. Em situações reais, já me deparei com casos onde, para atender às demandas do negócio, foi necessário ignorar algumas boas práticas de engenharia de software. Isso porque, no mundo real, essas práticas muitas vezes não encontram espaço no ambiente de produção. A realidade é que você vai lidar com transações deletadas, tabelas que sofrem atualizações manuais e até mesmo tabelas sem campos de controle como lastupdate.
Um bom engenheiro de dados vai identificar e apontar essas falhas no software de onde os dados estão sendo coletados. Porém, um excelente engenheiro vai além e encontra maneiras criativas de contornar essas lacunas.
É importante entender que o problema não está no negócio não querer que o software tenha esses campos de controle. A questão é que o negócio evolui tão rapidamente que o mesmo software que atende Joãozinho também precisa atender Maria e Pedrinho. Existem vários softwares de prateleira no mercado que são customizáveis, mas a adaptação sempre trará desafios.
Agora que você compreende a complexidade da situação, vou explicar como habilitar um Change Data Capture (CDC) em uma tabela no SQL Server. O processo também é aplicável a outras tabelas, e OLTPs como Oracle possuem processos similares.
Após habilitar o CDC, você estará apto a consumir esses dados de maneira controlada, mas lembre-se: habilitar o CDC tem suas peculiaridades.
Agora, chega de teoria e vamos ao passo a passo.
Change Data Capture (CDC)
É um recurso do SQL Server que permite rastrear mudanças (inserts, updates e deletes) em tabelas. Para realizar uma leitura incremental de uma tabela com CDC, você deve seguir alguns passos para configurar o CDC, consultar as alterações e aplicar essas mudanças conforme necessário.
Aqui está um guia passo a passo para realizar uma leitura incremental usando CDC:
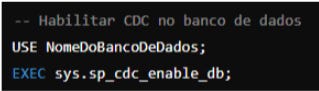
1. Habilitar CDC no Banco de Dados
Primeiro, você precisa habilitar o CDC no banco de dados onde a tabela está localizada.
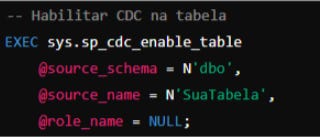
2. Habilitar CDC na Tabela
Depois de habilitar o CDC no banco de dados, habilite-o para a tabela específica que você deseja monitorar.
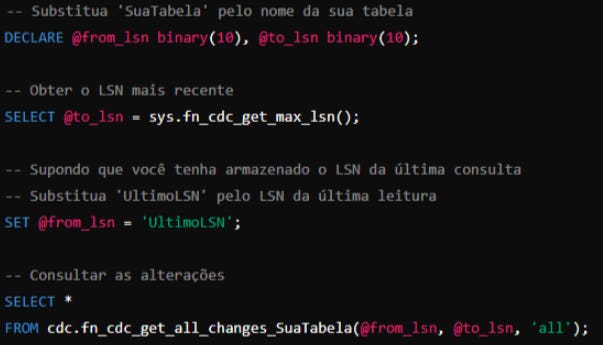
3. Consultar Alterações
Para realizar uma leitura incremental, você precisará consultar as tabelas de captura de dados. O CDC cria tabelas de captura de dados no esquema cdc, com um sufixo _CT anexado ao nome da tabela original. Essas tabelas contêm as alterações.
Para consultar as alterações, você usará a função cdc.fn_cdc_get_all_changes_<nome_da_tabela> ou cdc.fn_cdc_get_net_changes_<nome_da_tabela>. A diferença entre essas funções é que fn_cdc_get_net_changes retorna apenas as mudanças desde a última consulta (resumidas), enquanto fn_cdc_get_all_changes retorna todas as mudanças
Aqui está um exemplo básico de como consultar as mudanças:
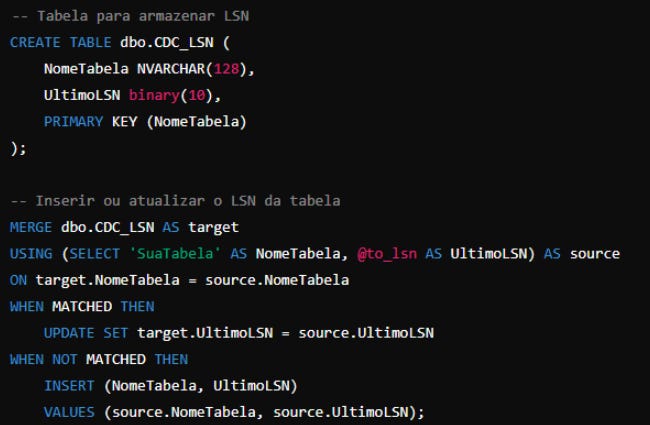
4. Armazenar e Gerenciar LSNs
Para realizar uma leitura incremental, você deve armazenar o LSN (Log Sequence Number) da última execução para que na próxima execução você possa buscar as mudanças a partir desse LSN.
Você pode armazenar o LSN em uma tabela dedicada, por exemplo:
5. Aplicar Mudanças
Depois de obter as mudanças, você pode aplicá-las ao seu sistema ou realizar qualquer processamento necessário. Dependendo do que você deseja fazer, você pode ter um processo que insere, atualiza ou exclui dados em seu sistema de destino com base nas mudanças capturadas.
Nesta etapa fica a seu critério, eu utilizo muito Strutered streaming do spark e CDF.
6. Limpeza de Dados CDC
CDC pode gerar uma quantidade significativa de dados ao longo do tempo. Certifique-se de configurar a retenção e a limpeza de dados para evitar o crescimento excessivo dos logs.

Resumo dos Passos
1. Habilitar CDC no banco de dados e na tabela.
2. Consultar alterações usando as funções CDC apropriadas e gerenciar os LSNs.
3. Armazenar LSNs para futuras consultas incrementais.
4. Aplicar mudanças conforme necessário.
5. Gerenciar o crescimento e a retenção de dados CDC.
Ao seguir esses passos, você pode configurar uma leitura incremental eficiente e eficaz usando Change Data Capture no SQL Server.
Por fim, obrigado a todos e espero que este artigo lhe ajude na sua missão.
Abraços Wellikiandre Martins.