


Usando CDF (Change Data Feed) no Databricks com Structured Streaming - Para leigos
Change Data Feed (CDF) + Spark Strutered Streaming


Prazer me chamo Wellikiandre Martins
🚀 Engenheiro de Dados Especialista | Arquiteto de Soluções Data & AI | Cloud Computing Azure & AWS | Expert Databricks & Apache Spark🌐 Profissional de Alto Desempenho | +12 Anos de Experiência | +38 Projetos Validados.
Quer aprender comigo ? Acesse Datacement: https://datacement.com.br/
Me siga: desconto 😉🚀❤️
Introdução ao Change Data Feed (CDF)
O Change Data Feed (CDF) no Databricks Delta Lake permite capturar mudanças incrementais nos dados armazenados em uma tabela Delta. Isso é útil para pipelines de dados, auditoria e sincronização eficiente entre sistemas.
O CDF rastreia as alterações (inserções, atualizações e exclusões) automaticamente e armazena essas informações para que possam ser consultadas facilmente. Além disso, podemos integrar o CDF com Structured Streaming, permitindo capturar mudanças em tempo real para processamento contínuo.
Habilitando o CDF em uma Tabela Delta
Para usar o CDF, a tabela Delta precisa estar configurada com a propriedade delta.enableChangeDataFeed. Isso pode ser feito durante a criação da tabela ou posteriormente.
Criando uma Tabela Delta com CDF
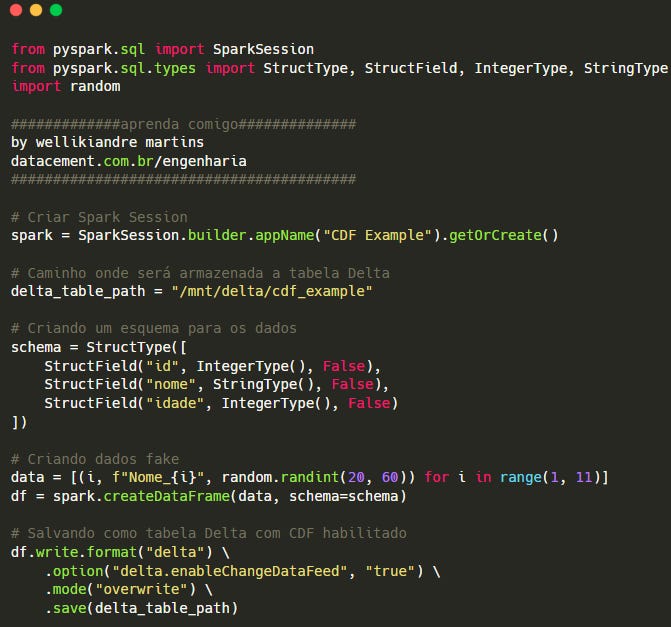
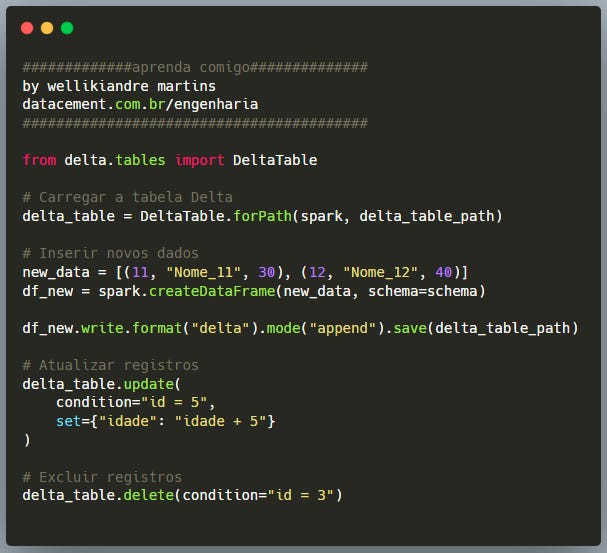
Alterando os Dados e Gerando um Change Data Feed
Agora que a tabela Delta está configurada com o CDF, vamos modificar os dados para gerar um histórico de mudanças.
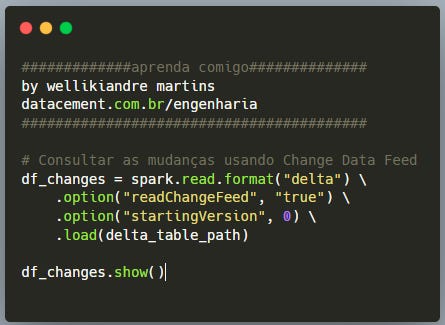
Consultando as Mudanças Usando CDF
Agora que realizamos alterações, podemos consultar o Change Data Feed para ver o histórico de mudanças.
O resultado incluirá colunas adicionais, como:
changetype: Indica o tipo de mudança (insert, update, delete).
commitversion: A versão da transação onde ocorreu a mudança.
committimestamp: O timestamp da alteração.
Usando CDF com Structured Streaming
Podemos utilizar o Structured Streaming para capturar as mudanças em tempo real e processá-las continuamente. Isso é útil para sincronização de sistemas, auditoria de dados e análises incrementais.
Criando um Streaming para Capturar Alterações
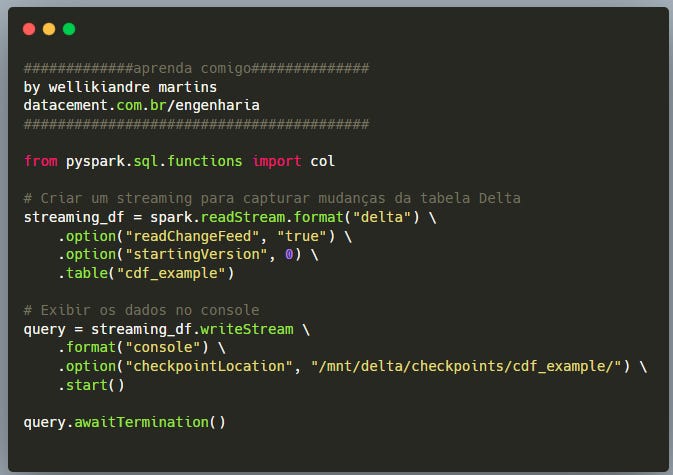
Explicação do Código
spark.readStream.format("delta") → Configura a leitura contínua da tabela Delta.
.option("readChangeFeed", "true") → Habilita a captura de mudanças via CDF.
.option("startingVersion", 0) → Define que o streaming começará a ler a partir da primeira versão da tabela.
.writeStream.format("console") → Exibe as mudanças em tempo real no console.
.option("checkpointLocation", "/mnt/delta/checkpoints/cdf_example/") → Define um local para armazenar o estado do streaming, garantindo que ele retome corretamente em caso de falhas.
.start() → Inicia o processo de streaming.
.awaitTermination() → Mantém o streaming rodando continuamente.
Estrutura de Pastas Criadas pelo Delta Lake
Quando usamos CDF e Structured Streaming, o Delta Lake cria uma estrutura de pastas específica dentro do diretório da tabela:
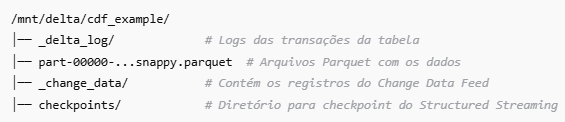
Explicação das Pastas
_delta_log/: Diretório onde ficam armazenados os logs de transações. Cada alteração na tabela cria um novo arquivo JSON de log.
Arquivos .parquet: São os arquivos que armazenam os dados reais da tabela em formato otimizado.
_change_data/: Diretório onde as mudanças rastreadas pelo CDF são armazenadas. Ele permite que o Spark leia apenas os dados que foram modificados em cada versão.
checkpoints/: Diretório onde o Structured Streaming salva checkpoints para garantir a continuidade da execução em caso de falhas.
Conclusão
O Change Data Feed (CDF) no Delta Lake simplifica a captura de mudanças em tabelas, permitindo processar apenas os dados alterados. Com o Structured Streaming, podemos capturar essas mudanças em tempo real, tornando o processamento de dados mais eficiente e escalável.
Essa abordagem é ideal para: ✅ Pipelines de dados incrementais ✅ Sincronização entre sistemas ✅ Monitoramento e auditoria de mudanças
Com a estrutura organizada e logs detalhados, o CDF + Structured Streaming é uma poderosa ferramenta para engenharia de dados no Databricks. 🚀